Data Preprocessing for Machine learning in Python
Data Preprocessing for Machine Learning in Python
Data Preprocessing is a technique that is used to convert the raw data into a clean data set. In simple words, pre-processing refers to the transformations applied to your data before feeding it to the algorithm.

Need of Data Preprocessing
QUALITY DATA :(Low Quality of data gives Low Quality of mining results
- Quality decisions must be based on quality data
e.g., duplicate or missing data may cause incorrect or even misleading statistics.
Tasks of Data Preprocessing
Different steps are involved for Data Preprocessing. These steps are described below -
Data Cleaning
This is the first step which is implemented in Data Preprocessing. In this step, the primary focus is on handling missing data, noisy data, detection, and removal of outliers, minimizing duplication and computed biases within the data.
Data Integration
This process is used when data is gathered from various data sources and data are combined to form consistent data. This consistent data after performing data cleaning is used for analysis.
Data Transformation
This step is used to convert the raw data into a specified format according to the need of the model. The options used for transformation of data are given below -
- Normalization - In this method, numerical data is converted into the specified range, i.e., between 0 and one so that scaling of data can be performed.
- Aggregation - The concept can be derived from the word itself, this method is used to combine the features into one. For example, combining two categories can be used to form a new group.
- Generalization - In this case, lower level attributes are converted to a higher standard.
Data Reduction
After the transformation and scaling of data duplication, i.e., redundancy within the data is removed and efficiently organize the data.
Different steps are involved for Data Preprocessing for ML in python
These steps are described below -
Step 1 : Importing the required libraries
These two are essential libraries which we will import everytime.
- Numpy is a Library which contains Mathematical functions .
- Pandas is the library used to import and manage the data sets.

Step 2 : Importing the Dataset
Data sets generally available in .CSV format.A CSV files stores tabular data in plain text.Each line of the file is a data record. We use the read_csv method of the Pandas library to read a local CSV files as a dataframe.
Then we make separate Matrix and Vector of independent and dependent variables from the dataframe.

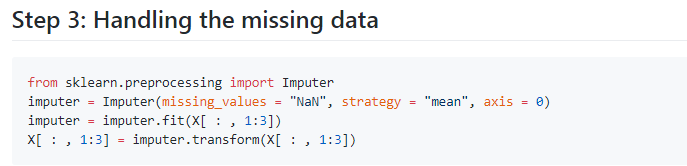
Step 3 : Handling the Missing Data
The data we get is rarely homogeneous Data can be missing due to various reasons and needs to be handled so that it does not reduce the performance of our machine learning model.We can replace the missing data by the Mean or Median of the entire column .
We use Imputer class of sklearn.preprocessing for this task.
Step 4 :Encoding Categorical Data
Categorical data are variables that contain label values rather than numeric values.The number of possible values is often limited to a fixed set.Examples values such as "Yes "and "No" cannot be used in mathematical equations of the model so we need to encode these variables into numbers .To achieve this we import LabelEncoder class from sklearn.preprocessing library.

Step 5 : Splitting the dataset into test set and training set
We make two partitions of dataset one for training the model called training set and other for testing the performance of the trained model called test set .The split is generally 80/20. We import train_test_split() method of sklearn.crossvalidation library.

Step 6 : Feature Scaling
Most of the machine learning algorithms use the Euclidean distance between two data points in their computations.features highly varying in magnitudes.units and range pose problems .high magnitudes
features will weigh more in the distance calculations than features with low magnitudes.Done by Feature standardization or Z-score normalization.standardscalar of sklearn.preprocessing is imported.

References:
- https://www.analyticsvidhya.com/blog/2016/07/practical-guide-data-preprocessing-python-scikit-learn/
- https://www.geeksforgeeks.org/data-preprocessing-machine-learning-python/
- https://github.com/Avik-Jain/100-Days-Of-ML-Code(refer for code AND dataset)

Nice basic foundation article for Data .... Keep it up Laxmi
ReplyDelete